Data or Drivel?

I saw an article recently appearing on Medium.com written by Bill Pardi, a data science engineer at Microsoft. The article was directed at creative works and data driven design, but I found it very applicable to the digital forensic space, especially this quote from Beau Lotto:
"There is no inherent value in any piece
of data because all information
is meaningless in itself. Why?
Because information doesn't tell
you what to do."
That's something to think about. The artifacts our tools so dutifully extract and present to us, in and of themselves, aren't very informative as to what they indicate or if they're even relevant. That depends to a large degree on the expertise of the examiner. Artifacts related to shell bags may not seem important at all to an examiner not familiar with what those are or how they work. The effect is compounded many times over due to the condition that it's never just one artifact the examiner needs to interpret, but tens of thousands or hundreds of thousands of artifacts.
I absolutely subscribe to the idea that a competent examiner is one who is thoroughly trained to use the tools they employ, extensively knowledgeable regarding the technology being examined, and well versed in the nuances of law pertaining to the examination at hand. Even so, I see a gap between a pure latent artifact extractor which is our tool and reasonable inferences that might be made by that tool. Many newer tools are presenting more and creative ways to visualize data. Few who have examined both can argue that sometimes a simple graph can be more informative to the eye than a spreadsheet. Looking at a list of potentially relevant telephone numbers together with geolocation data is far less informative than the same data charted in clusters on a map with connecting lines between those telephones that have mutual contact data. This is several steps in the right direction and itself doesn't replace training/education requirements for the examiner.
Further in Pardi's article he states, "Data is not reality". He illustrates how human bias will and should influence the data interpretation. The ideal forensic examination is bias free, just as a well constructed scientific experiment has the same expectation. The difference is in where the bias is applied. An examiner whose education and experience is thorough regarding Peer-2-Peer (P2P) forensic investigations will "read" the data differently than an examiner with less P2P experience/education. The same will be true if the education/experience is only somewhat different. An expert regarding Limewire client artifacts who has little experience with Transmission clients will inherently cast a different eye on the data than someone who has more Transmission knowledge. It doesn't matter how many Transmission artifacts the tool can dig up if little or none of it impacts the investigative results. The data, on its own, is not reality.
Pardi goes on to say that, "All data is missing something". I took two things away when I read this: #1, incomplete data is incomplete and, #2, flawed logic results in flawed interpretations. His example of the Linda profile is readily apparent as incomplete. The truth of the matter is that most data comprised of forensically derived artifacts will be incomplete. It would be great if a strict quantifiable number of artifacts could be determined as the ideal number required to prove a given behavior or condition. Reality isn't so neat and doesn't allow for this type of quantification. Or, better yet, if artifacts could be absolutely weighted by percentage so that once enough artifacts have been discovered to push the total percentage of proof beyond some baseline, say 98%, then we've reached the state of "beyond a reasonable doubt". That condition doesn't exist, either, and is the reason we need courts of law to weigh the strength and validity of evidence in the first place. This leaves the examiner in the position of logically considering and sorting all the potentially relevant artifacts via education and experience... and we're back at square one: data overload and heavy reliance on examiner knowledge and intuition.
My second take away was flawed logic results in flawed interpretations. Pardi uses two categories to classify Linda: that she is a bank teller or that she is a bank teller active in women's rights. The discriminator is to choose the most probable category. Based on information in the Linda profile, Pardi explains that most people would pick the second classification, that she is a bank teller active in women's rights. She may certainly be active, but this is not guaranteed based on the profile information. An examiner drawing this conclusion must do so as a matter of objective probability. Even so, choosing this category misses the point of the categorization, which is to determine which category is "most" probable. Since "bank tellers active in women's rights" also belong to the category of "bank tellers", the first category would be most probable since it accounts for both possibilies that Linda is or is not active in women's rights. An examiner's flawed application of logic and reasoning, specifically abductive, inductive, and deductive, results in flawed interpretations. This can still be useful, however, as we will see...
"More data, less clarity", is another point Pardi makes. He uses Duncker's Candle Problem to illustrate. Basically, participants are given a candle, a box of thumbtacks, and a book of matches, then instructed to mount the candle on the wall without dripping any wax from the lighted candle on the table below. I won't give the solution away before you explore the link, but suffice it to say that most people either fail to solve the problem or attempt to do so in very complicated ways. How is this applicable to digital forensics?
There are artifacts that may not indicate what they seem. For example, not all file created dates make sense when compared to file accessed or modified dates. This has to do with how the file came to be located on the digital media, that media's file system, and the file system of the media that the file was transferred from. A question might arise as to how a file's created date can be later than its accessed date. The answer depends on the conditions I mentioned.
Further, there are hundreds of thousands of files, and potentially an exponential number of individually related artifacts, present in the average home computer or mobile device. The potential for relevant artifacts obviously increases with the amount of data present, but the identification of those artifacts doesn't necessarily follow. A searcher's likelihood of finding a needle in a haystack doesn't increase by simply adding another needle-bearing haystack, only the amount of time, effort, and expense required to search them both. At the end of the day, the examiner is still left with only needles and his/her own expertise as to what those needles truly mean to the investigation, if anything.
Pardi gives some good advice to creatives seeking to make the most of data and this is where we'll depart. I'd rather focus on what our tools could be doing for us that they're not. As I said previously, data visualization is several steps in the right direction. Another avenue that seems to be generally unexplored is use case templating. By this, I mean using templates to focus forensic investigative effort. This isn't data reduction per se, but I'd like to explore that concept first.
Data reduction is just that: reducing data to be examined. A data scientist might call it reducing sample size. It is those efforts aimed toward culling out irrelevant data so that more relevant data can be examined. A great way to do this generally is making use of NIST's NSRL RDS. NIST (National Institute of Science and Technology) maintains the National Software Reference Library (NSRL) and publishes a Reference Data Set (RDS). From their website:
"This project is supported by the U.S. Department of Homeland Security, federal, state, and local law enforcement, and the National Institute of Standards and Technology (NIST) to promote efficient and effective use of computer technology in the investigation of crimes involving computers. Numerous other sponsoring organizations from law enforcement, government, and industry are providing resources to accomplish these goals, in particular the FBI who provided the major impetus for creating the NSRL out of their ACES program.
The National Software Reference Library (NSRL) is designed to collect software from various sources and incorporate file profiles computed from this software into a Reference Data Set (RDS) of information. The RDS can be used by law enforcement, government, and industry organizations to review files on a computer by matching file profiles in the RDS. This will help alleviate much of the effort involved in determining which files are important as evidence on computers or file systems that have been seized as part of criminal investigations.
The RDS is a collection of digital signatures of known, traceable software applications. There are application hash values in the hash set which may be considered malicious, i.e. steganography tools and hacking scripts. There are no hash values of illicit data, i.e. child abuse images.
Tools that make use of the RDS generally do so as a filter mechanism to remove known files from the data to be processed and examined. Once a file has been hashed, that value is compared to the RDS. If it matches, the file can be safely filtered out of the remaining processes. This speeds up processing time by only processing those files that are unknown to the RDS. Does this mean, then, that those remaining files are bad? No. In fact, no such assumption can be made at this point since it's entirely likely that software makers are releasing new software even at this very moment with files that didn't exist before now. They're entirely legitimate, however unknown as yet by RDS.
Focused processing in an effort to specifically target data based on use case comes after pure data reduction. One tool that has a unique approach to this and is very simple to use is Autopsy's Interesting Files Identifier Module. Autopsy is the brainchild of Dr. Brian Carrier with Basis Technology. It started as a browser-based front end to The Sleuth Kit and has grown into a fully featured forensic platform suite used by examiners worldwide. More than that, it's FOSS with excellent contributor documentation and community support.
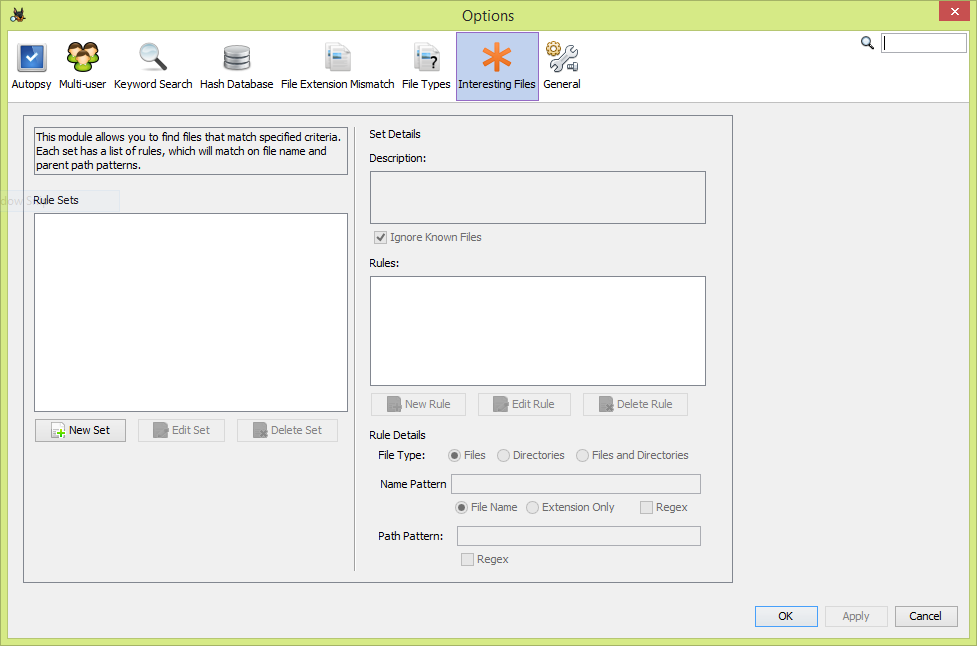
The Interesting Files module is a bit of an unsung hero, but is one of the most useful features of Autopsy. That's saying quite a bit as there are many useful features, but the utility of this module can't be overemphasized. It's based on simple rules that are organized into sets. This module doesn't replace the need for examiner knowledge and expertise, but does provide a way to tailor and focus an investigation based on use cases. We'll walk through an example...
The module is configured in Autopsy's global settings. In the main menu, select “Tools”, then “Options”, then the "Interesting Files" tab (orange asterisk). This contains settings that allow the examiner to custom design search criteria for files and/or folders that might be of interest. The Autopsy documentation explains that it works as a "File Alerting Module" by generating messages in the examiner's inbox when specified files are found. Unless custom rule sets are created, the module does nothing since there are no default rule sets. Additionally, this module depends on the Keyword Search module since it works against indexed data. Without indexed data, the module does nothing.
We'll create a rule set applicable to a P2P use case involving the Transmission bittorrent client. Transmission is open source and is available for Windows, Macintosh, and GNU/Linux computers. This makes it a commonly used application and one that is likely to show up in your real world examinations later.
According to the developer documentation for Transmission, there are at least three directories and two files of potential interest. These are the torrents, resume, and blocklists directories, along with the settings.json and stats.json files. Another thing to note is that there are some differences between Transmission artifacts on Windows, OS X, and GNU/Linux installations. We'll create artifact rules for all three systems.
To begin, select the "New Set" button under the "Rule Sets" pane of the Interesting Files window. This opens an Interesting Files Set window. Enter a name for your new rule set and provide an optional description. Also select the checkbox if you want the module to ignore known files, such as NSRL RDS, then select "OK". We use "P2P Artifacts" for this example:

For
this rule set to be useful, we need to add at least one rule. Select
the "New Rule" button in the "Set Details"
section of the window on the right side and under the "Description:"
if you added one and the "Rules:" areas. This opens an
Interesting Files Set Rule window. "Type*:" is a radio
button selection of Files, Directories, or Files and Directories
which identifies the nature of what the examiner is seeking to find.
"Name Pattern*:" can be a complete file or folder name, a
file extension only, or a regex using wildcard characters. This
nature of the name pattern is selected with one of two radio buttons
and a checkbox to declare whether or not the pattern should be read
literally or expanded by Autopsy as a regex. Both Type and Name
Pattern are required fields.
Optionally,
a "Path Pattern:" can be specified, either literally or as
a regex. The full expected file path need not be specified, only as
much as needed to identify the file being searched for as unique to
the examiner's interest. For example, files named "README.txt"
might be found scattered through a Windows XP hard disk drive.
Consider an examiner desiring to create a rule to find an expected
file named "README.txt" that's known to be commonly located
in C:\Program Files\Autopsy-4.4.0\. Searching only for "README.txt"
is likely to turn up many false positives. An added benefit of not
using the full path is that the file in question should likely be
found even if it was installed in a location other than the default
path. By adding a Path Pattern of /Autopsy-4.4.0/, Autopsy will only
note "README.txt" files that are in parent directories
named "Autopsy-4.4.0", which will presumably actually
identify only one file. Note that the directory name delimiter (path
separator) is the forward slash "/" as is common to UNIX
file systems even if we are searching a Windows image or file system.
Our
first rule simply finds the settings.json file that holds all the
client's settings and preferences. Here are the parameters:
Type*:................... Files
Name
Pattern*:... settings.json
(Full
Name)
Path
Pattern:..... /transmission/
Rule
Name:........ Transmission - Settings File
Finally,
give your rule a name and select the "OK" button.

This
rule will now find Transmission's JSON-formatted settings files on
either Windows or GNU/Linux installations. To find this file on an OS
X system, we need a second rule:

While
Transmission settings are typically stored in a JSON file, they're
stored instead in an XML-based plist file on OS X. They're both
readable in Autopsy. Both types of settings file can provide us
information pertaining to the user's global Transmission settings,
including the download directory, and can be compared against default
to see what, if anything, has been changed.
Let's
add a third rule. This time we may want to know various information,
such as:
-
If any torrent files have been made available to Transmission and what those files are.
-
Session statistics, to include upload/download byte counts.
-
If download of a particular torrent was initiated, which parts have been downloaded, and the download folder.
-
Possibly more...

This
rule works on all three operating systems.
The Interesting Files module is still artifact digging and any significance of the artifacts or relevance between artifacts is still purely left to the examiner to establish, so it's not quite the perfect solution I envision. Still, it represents a very powerful way to tailor an investigation without having to be a programmer or scripter.
The Interesting Files module is still artifact digging and any significance of the artifacts or relevance between artifacts is still purely left to the examiner to establish, so it's not quite the perfect solution I envision. Still, it represents a very powerful way to tailor an investigation without having to be a programmer or scripter.


Comments
Post a Comment